✨ X2SAM ✨
Any Segmentation in Images and Videos
📧 Corresponding author
Multimodal Large Language Models (MLLMs) have demonstrated strong image-level visual understanding and reasoning, yet their pixel-level perception across both images and videos remains limited. Foundation segmentation models such as the SAM series produce high-quality masks, but they rely on low-level visual prompts and cannot natively interpret complex conversational instructions. Existing segmentation MLLMs narrow this gap, but are usually specialized for either images or videos and rarely support both textual and visual prompts in one interface.
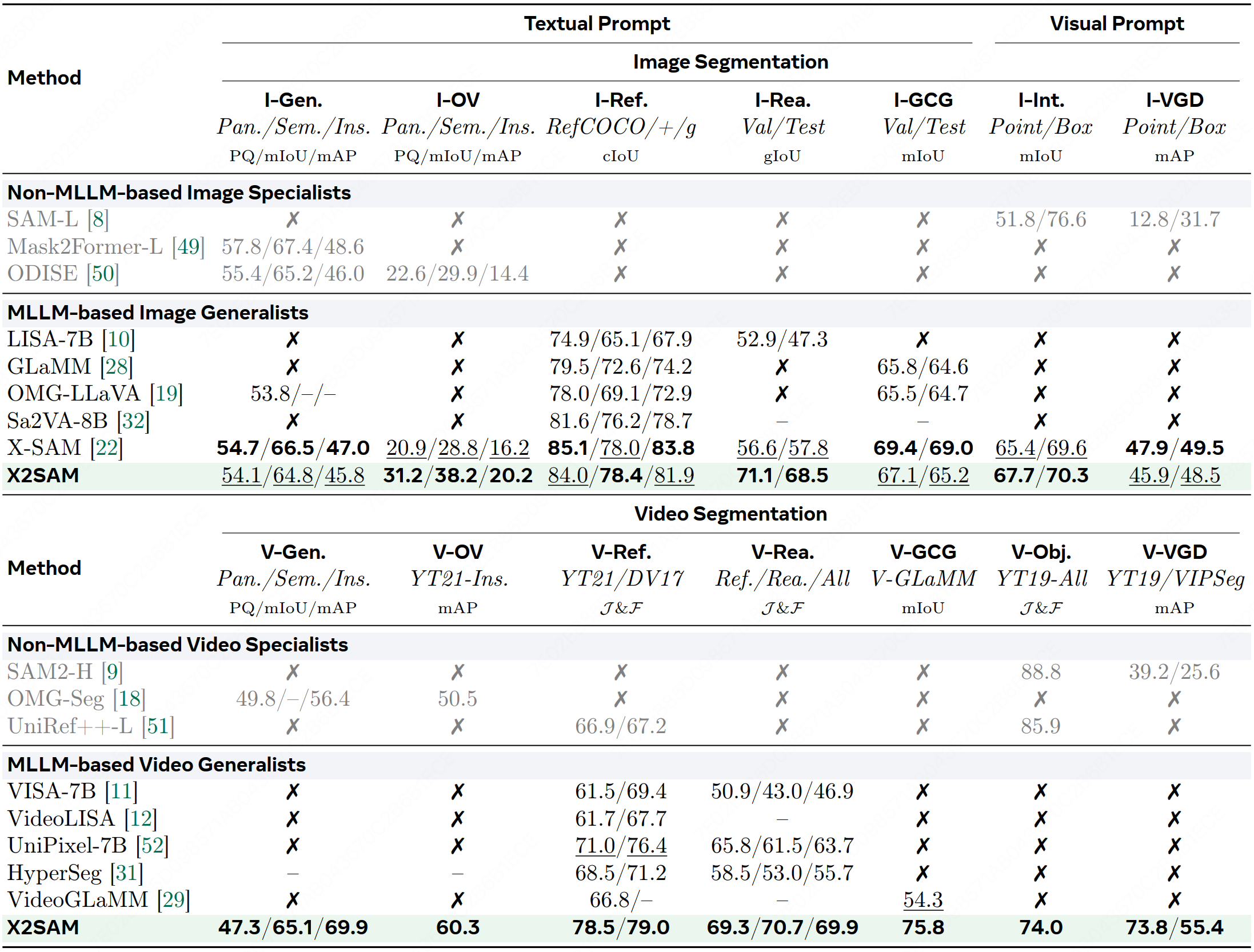
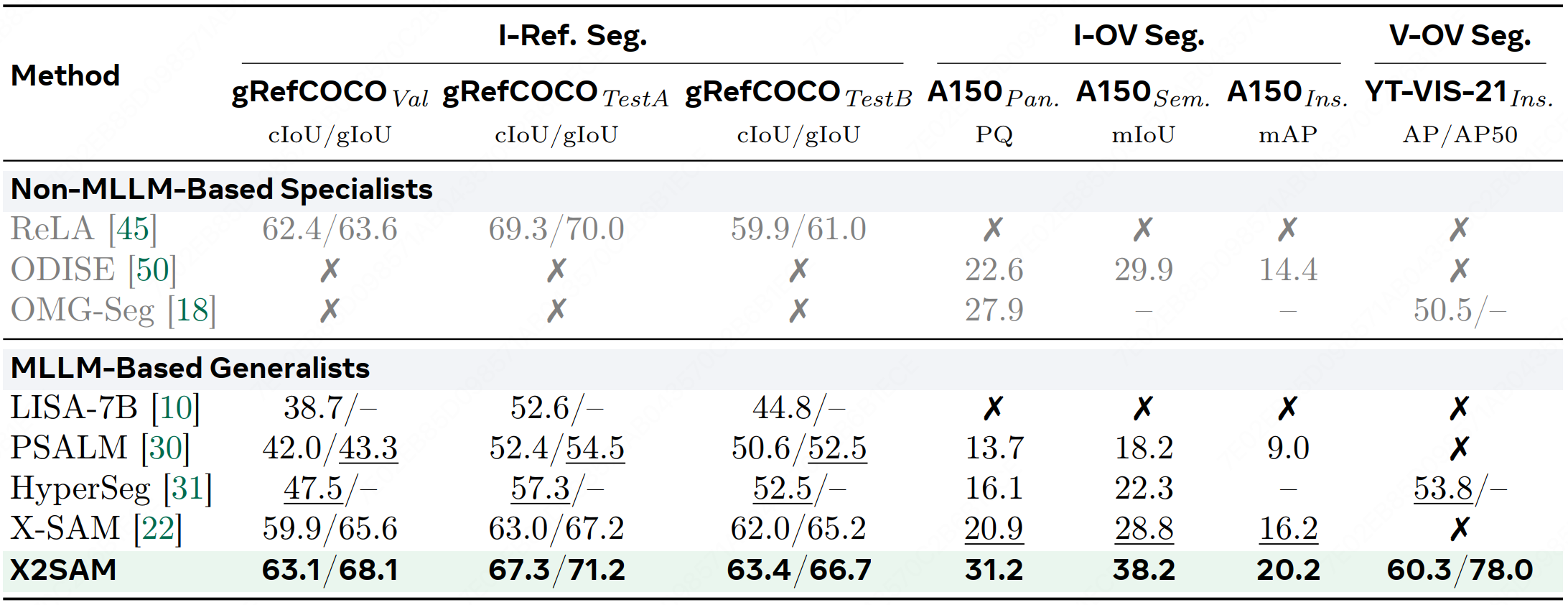
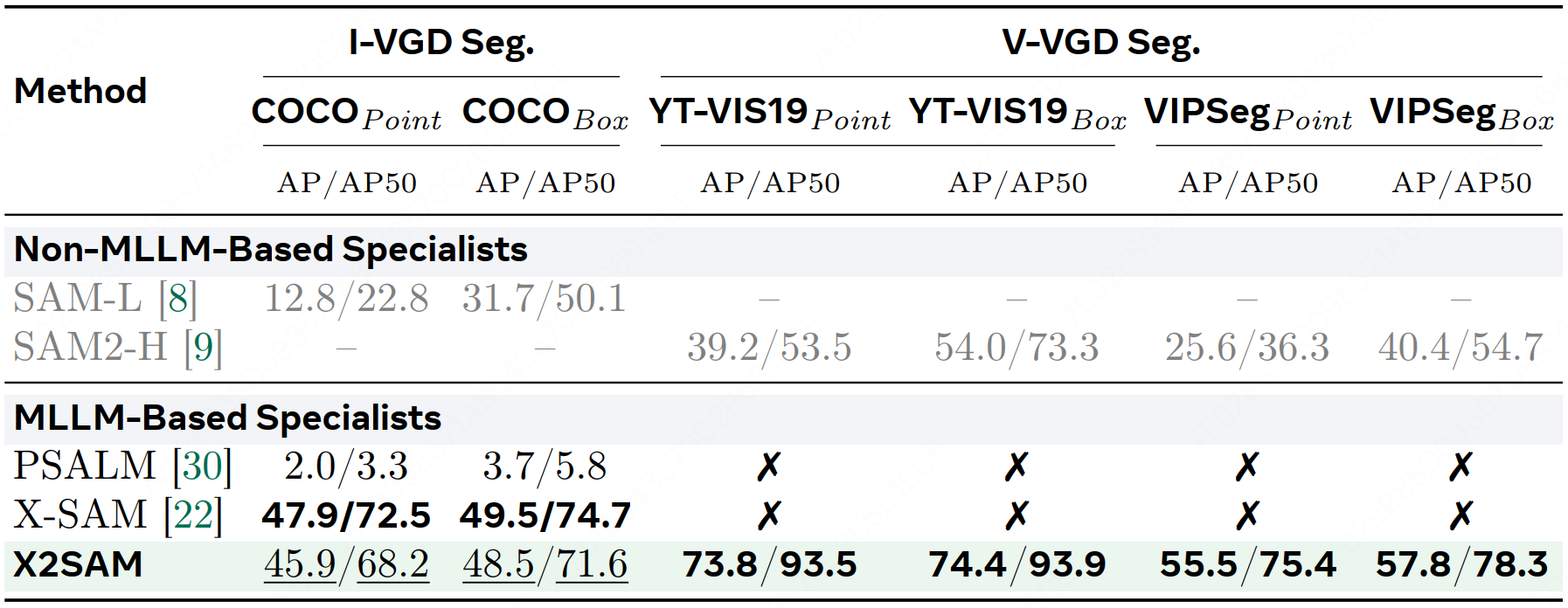
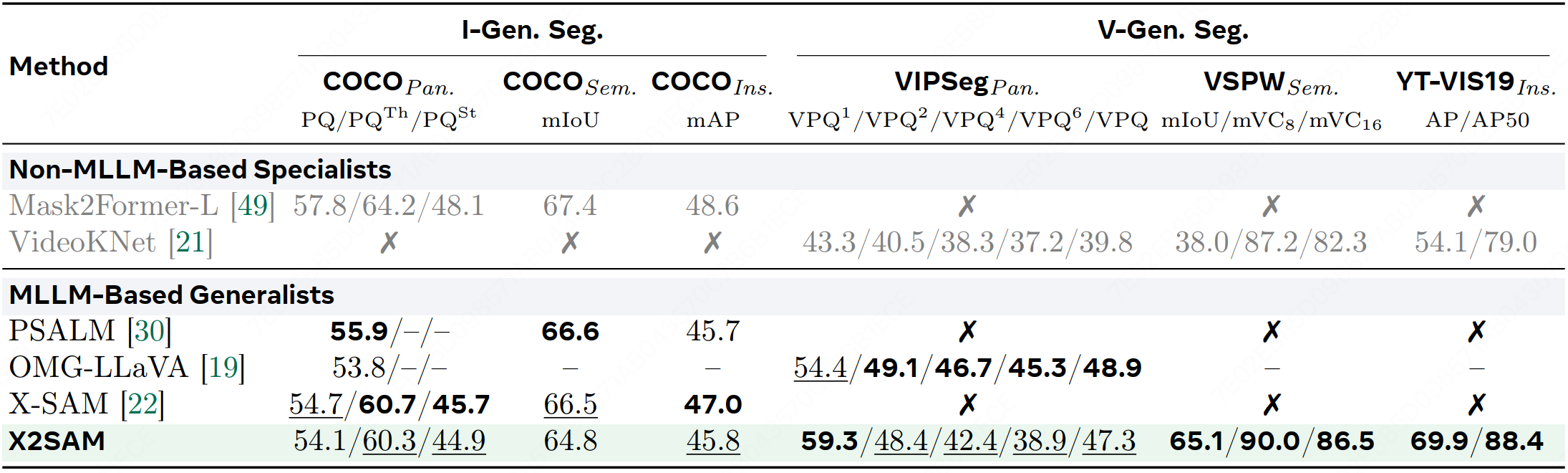
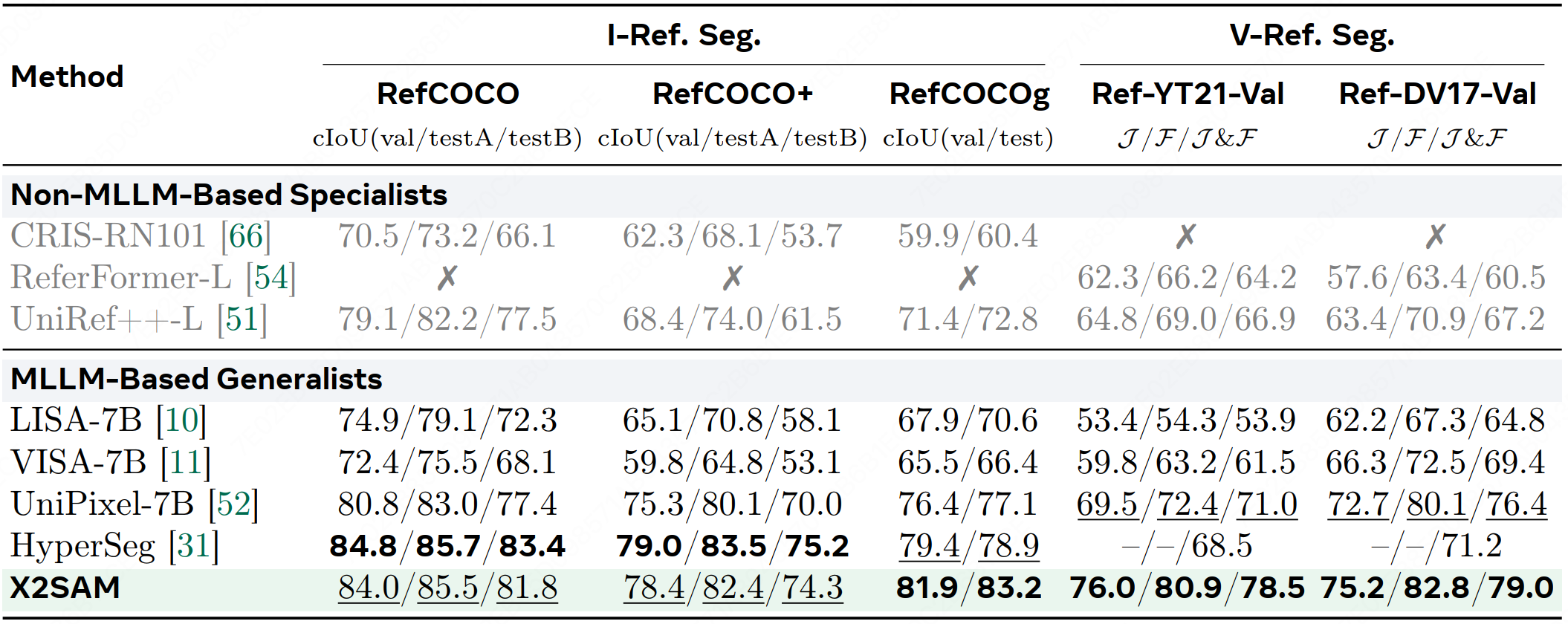
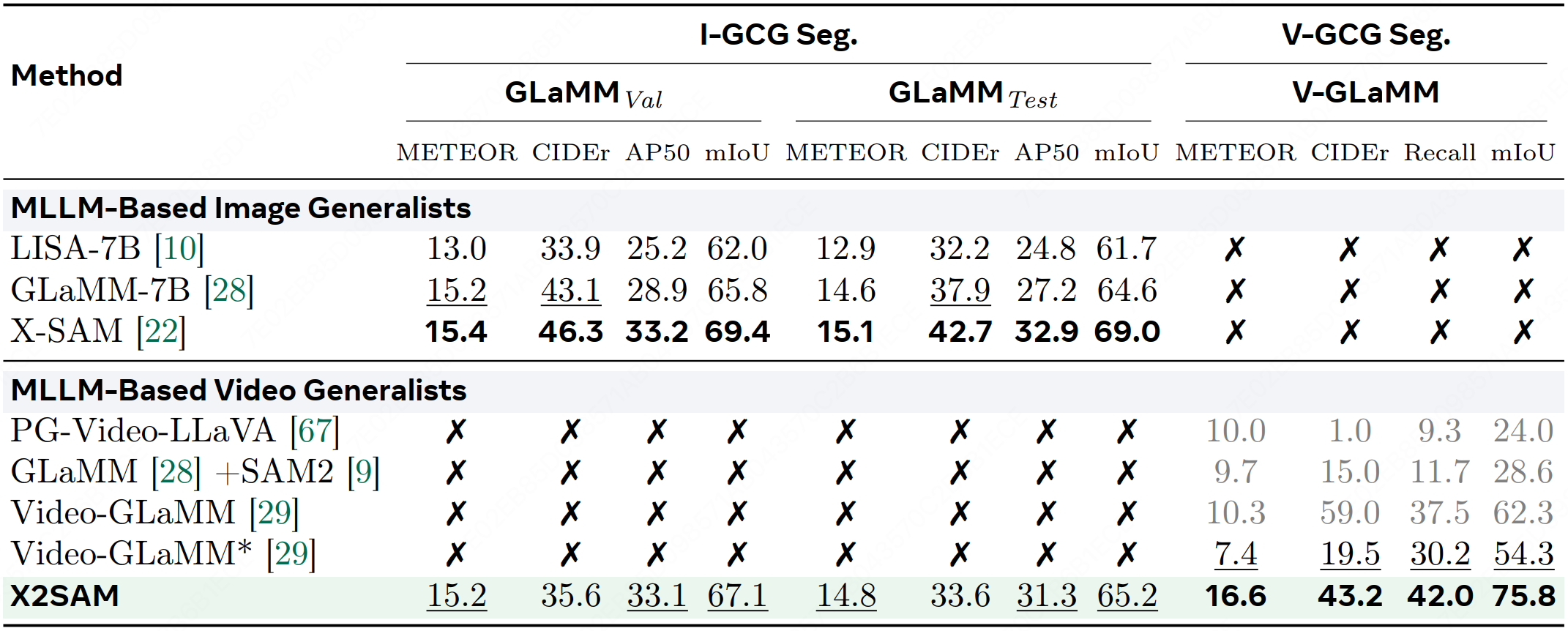
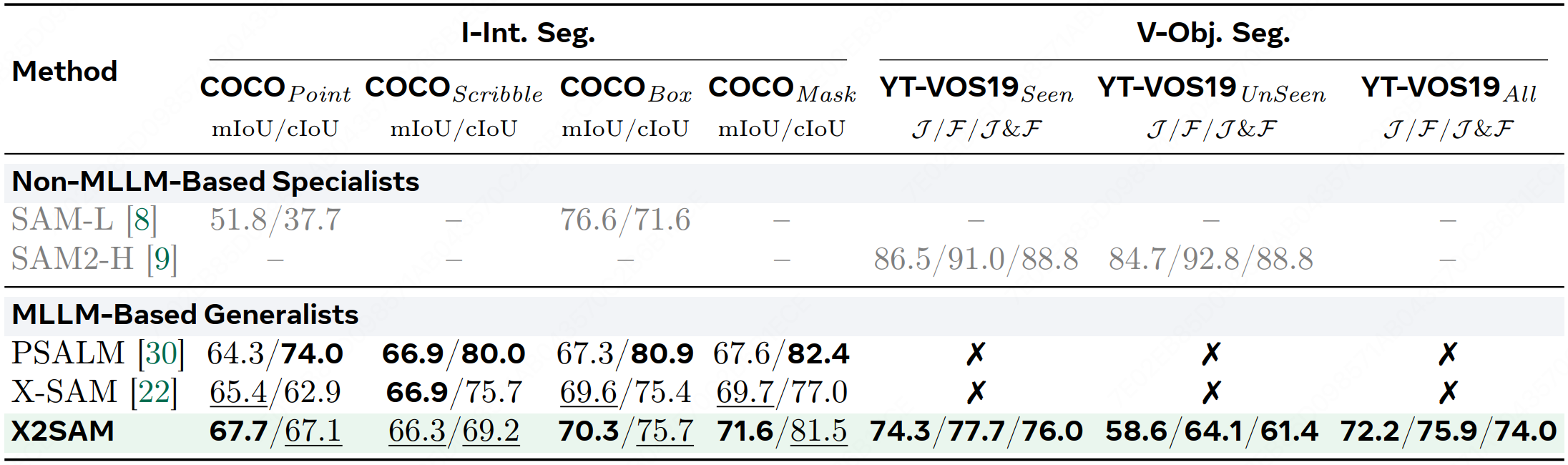
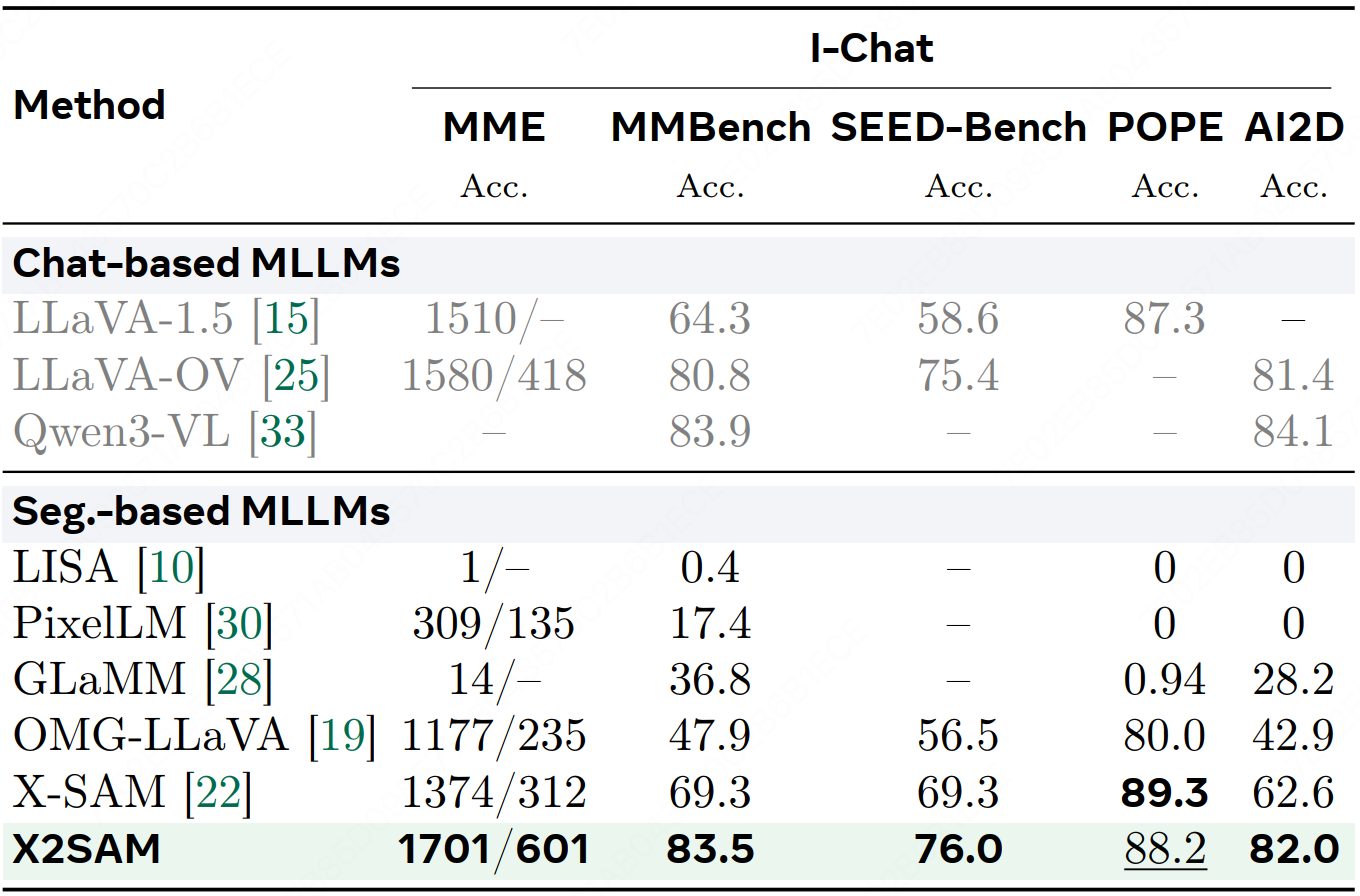
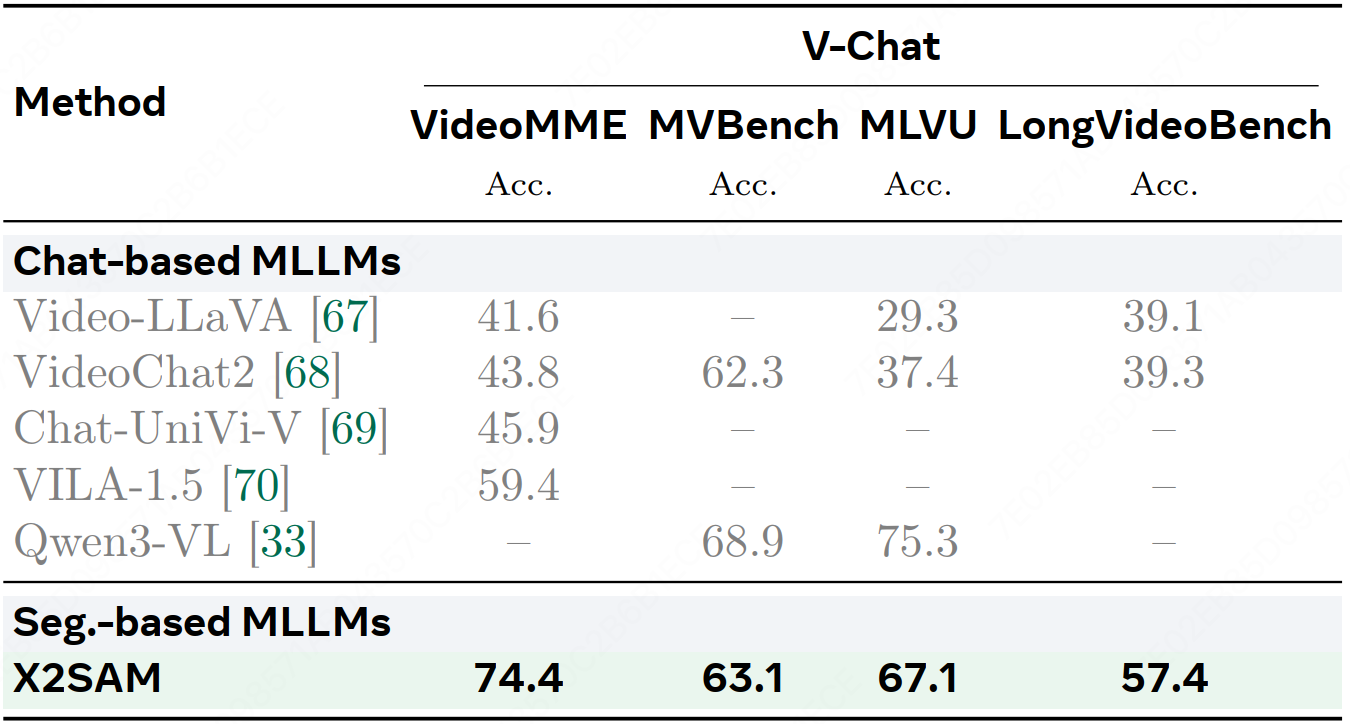
We introduce X2SAM, a unified segmentation MLLM that extends any-segmentation capabilities from images to videos. Given conversational instructions and visual prompts, X2SAM couples an LLM with a Mask Memory module that stores guided vision features for temporally consistent video mask generation. The same formulation supports generic, open-vocabulary, referring, reasoning, grounded conversation generation, interactive, and visual grounded segmentation across image and video inputs. We further introduce the Video Visual Grounded (V-VGD) segmentation benchmark, which evaluates whether a model can segment object tracks in videos from interactive visual prompts. With a unified joint training strategy over heterogeneous image and video datasets, X2SAM delivers strong video segmentation performance, remains competitive on image segmentation benchmarks, and preserves general image and video chat ability.


@article{wang2026x2sam,
title={X2SAM: Any Segmentation in Images and Videos},
author={Wang, Hao and Qiao, Limeng and Zhang, Chi and Wan, Guanglu and Ma, Lin and Lan, Xiangyuan and Liang, Xiaodan},
journal={arXiv preprint arXiv:2605.00891},
year={2026}
}
@inproceedings{wang2026xsam,
title={X-SAM: From segment anything to any segmentation},
author={Wang, Hao and Qiao, Limeng and Jie, Zequn and Huang, Zhijian and Feng, Chengjian and Zheng, Qingfang and Ma, Lin and Lan, Xiangyuan and Liang, Xiaodan},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={40},
number={31},
pages={26187--26196},
year={2026}
}